
The holistic data risks impacting your business
25 Mar 2021Data can be a significant asset that adds value to every business, but it includes some fundamental risks. Nikhil Asthana explains the twelve critical data risks impacting the data lifecycle in your organisation.
As data science techniques continue to develop, data capabilities are expanding every day. More and more firms use data analytics and visualisation to gain business intelligence and identify efficiencies. Machine learning and artificial intelligence are gradually becoming business staples, supporting self-service activities and automated processes. Data is also driving decision-making processes, improving business controls and offering market insight. In short, businesses want more from their data than ever before. But these increased expectations lead to increased risks.
The 12 holistic data risks
A robust data risk framework takes a holistic approach to risk management, embedding controls at every point along the data journey from source (ingestion) to business intelligence. From risks around data protection and reputation, there are also significant conduct, third party or social media risks to consider. We look at twelve holistic data risks and the key controls to mitigate them.
The data lifecycle
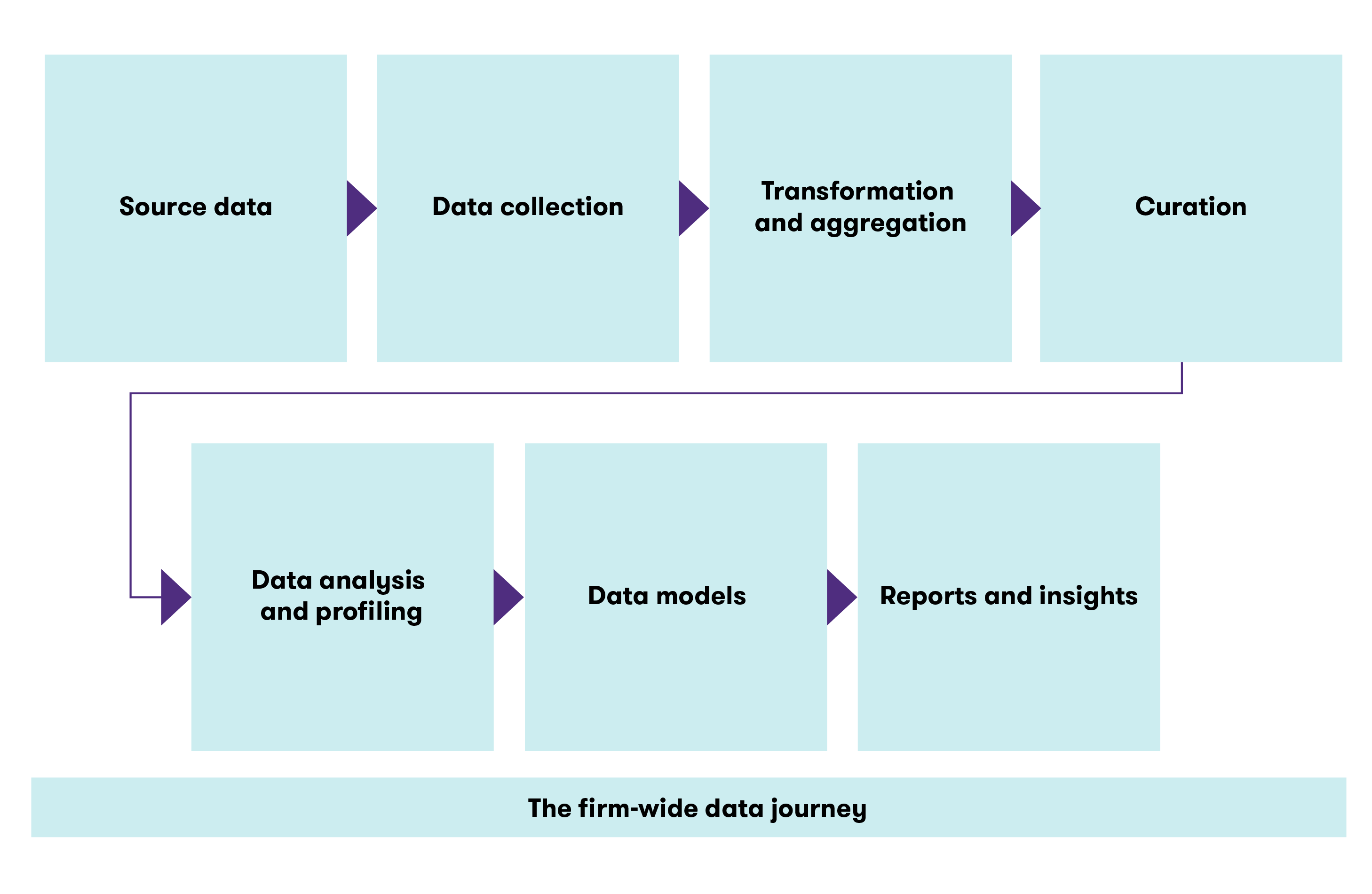
1 Data protection and GDPR
The General Data Protection Regulation (GDPR) has been in effect for a couple of years, but it is inherently complex and remains an ongoing challenge for many firms. It applies to the personal data of all EU citizens, regardless of where the organisation is based, and includes greater individual rights, rules on outsourcing and further guidance for retention and deletion. With significant fines, enforced by the Information Commissioner's Office (ICO), data breaches can be costly for the business – both financially and reputationally.
2 Data ethics
The high-profile Cambridge Analytica case sharpened the focus on the importance of ethics in data collection. An ethical approach to data offers greater transparency over the information collected, and how and why it is being used, and clarity over any decision-making processes it is informing. This is particularly challenging when applying machine learning or artificial intelligence, where there may be data biases or problems explaining the model.
It is important to have a data ethics policy (integrated within the overall data policy), which lays out the limits of what a firm is prepared to do with customer, employee, supplier and publicly available data. Personalisation versus segmentation of data is also an ongoing concern, and each organisation needs to decide a position in line with its risk appetite.
3 Data management fundamentals
In our previous article, we looked at the importance of getting the fundamentals of data management in place. As a recap these are data governance, metadata management, data quality, data lineage, data architecture, and reference data. Poor quality data or metadata with unclear lineage can limit its usefulness. Unreliable data is a liability and can cause negative outcomes in decision-making processes. Similarly, data that is not properly labelled or tagged may be stored or handled incorrectly, giving rise to potential breaches of GDPR and other regulations. Clear ownership and accountability, supported by appropriate data architecture, will help to mitigate these risks.
4 Cyber risk management
Cyber security processes aim to prevent unauthorised access to a network or end terminal, which can have a knock-on impact on data security. A successful cyber-attack can result in data poisoning, corruption or leakage. Key controls to prevent a successful cyber-attack or breach include appropriate network configuration, patch processes, staff training (including phishing) and web content filtering (amongst others).
5 Information risk management
Appropriate data classification will tell firms how that data should be stored, handled or used and what additional controls are needed to mitigate the associated risks. Effective access management controls can also reduce unauthorised access internally, or by a third party in the event of a breach.
6 Data leakage and loss
Loss of personal data can lead to significant fines under the GDPR and be reputationally damaging. Leaked proprietary information can reduce competitiveness and be harmful to the wider business strategy. Similarly, corrupted data may cause operational disruption, with regulatory implications.
7 Monitoring third parties using data
If an organisation shares its data with a third party for processing, the user organisation remains the data controller. In financial services, regulated firms rely on hundreds and sometimes thousands of third parties (such as credit reference agencies or mortgage advisors) to process data for a range of operational, customer service and fulfilment reasons.
Data breaches and unauthorised use of data by these suppliers could result in a major reputational damage for the regulated financial services organisation, as well as regulatory censure by the ICO. They must monitor the service provider to make sure the data is processed according to data protection law and in line with other regulations.
For all regulated outsourced services, the compliance responsibility remains with the user organisation not the service provider. Supplier contracts alone are not enough to satisfy this obligation and require focused assurance activity.
8 Managing third-party data
A data controller decides how to use and process information, while a data processor will action those use cases. When processing third party data, it’s important to adhere to all regulatory or legal requirements, with appropriate evidence to demonstrate compliance. Service auditor reports may offer assurance in this space.
9 Social media marketing/h4>
Once again, the legacy of Cambridge Analytica highlights key ethical considerations for data usage which includes the use of social media. Additionally, most social media platforms cross so many jurisdictions that it can be a challenge to apply GDPR when assessing, collecting or leveraging data. An organisation needs to risk-assess carefully when considering sharing data with social media platforms and potential reputational damage.
10 Model data risk
When applying models, machine learning or AI, data integrity is essential – again highlighting the importance of good data quality, lineage and governance. Incorrect data feeding into these models can skew decision-making processes, create bias or generate unreliable outcomes for risk management purposes. This can have a legal and regulatory impact, leading to unfair treatment of customers, poor financial crime controls and impacting a myriad of risk management frameworks.
11 Data execution risk
There are additional risks when key data processes are executed, for example migration, testing or extraction, transformation and load processes (ETL). Lack of skilled data management and technology specialists, ineffective project management, poor governance or lack of business engagement can impact the success of these activities, introducing further risks when manipulating data to its target end state.
12 Data decisioning
In data driven decision-making processes, getting the algorithm right is crucial. This relies on getting the correct historical data sets, coupled with the right skills sets, both to undertake the work and offer assurance over it. Some degree of bias will always be present, and it is important to take steps to mitigate it. Data-based decision-making processes must always be reliable, repeatable and trustworthy, including key regulatory implications for fair treatment of customers. Predictive algorithms make decisions on lending and investment, based on historical social, ethnic and gender data and must be carefully reviewed for bias.
Meeting the challenges of data risk
Poor data management can give rise to legal, regulatory and conduct risks, with a significant impact on a firm’s reputation and revenue. These risks need to be considered at every point where data is collected, stored, managed or handled across the organisation. Appropriate training, supported by the right data ethics and culture, will help embed holistic data controls across the business.
![]()