Report
Charity sector development report 2024
Find out more about emerging risks and issues in the charities sector, including changes to FRS 102, in our report.














Regulators are increasingly focused on how firms oversee, govern, and mitigate their model risk. This is reflected in last year’s consultation paper from the Prudential Regulation Authority (PRA), addressing ‘model risk management principles for banks’. Despite the banking focus, the key messaging is equally applicable to insurers and can help you achieve good practice and reduce model risk.
Poor oversight can lead to inaccurate models and limited management information, negatively impacting decision-making processes. There’s also greater potential for financial losses and misstatements, as well as inaccurate regulatory reporting. This can lead to regulatory fines or intervention to remediate issues.
There are many ways to manage model risk, and insurers should use methods that work for them. However, you should always consider if your approaches are fit for purpose and remain relevant. This is especially important as models and business changes over time. This year in particular, insurers are transitioning to IFRS 17, and some will have developed models in haste. Insurers will want to guarantee that model risk is managed around IFRS 17 as the dust from implementation settles.
Traditionally, model risk management in the first line of defence is through baselining, but there's also increasing focus in the second line in building model validation capabilities. The scope of baselining can vary from insurer to insurer, but there's a tendency to focus on the model logic with the data being assumed to be correct. When baselining a model, it’s important to look beyond the model logic itself to include data, data transformations, and underlying assumptions. While companies may have controls over each component separately, a joined-up view reduces risk of unintended interactions between data and the model.
Before starting a baselining exercise, a review should be performed on any existing documentation on data, transformations, model engine, and past baselining results. This review will inform you of any gaps or areas where more attention should be given during the baselining exercise.
The starting point for a baselining exercise is a dump of all data from the policy administration system. From there, you can take a sample of policies with a range of different features.
A typical baseline exercise, based on a best estimate liability (BEL) model, might look like this:
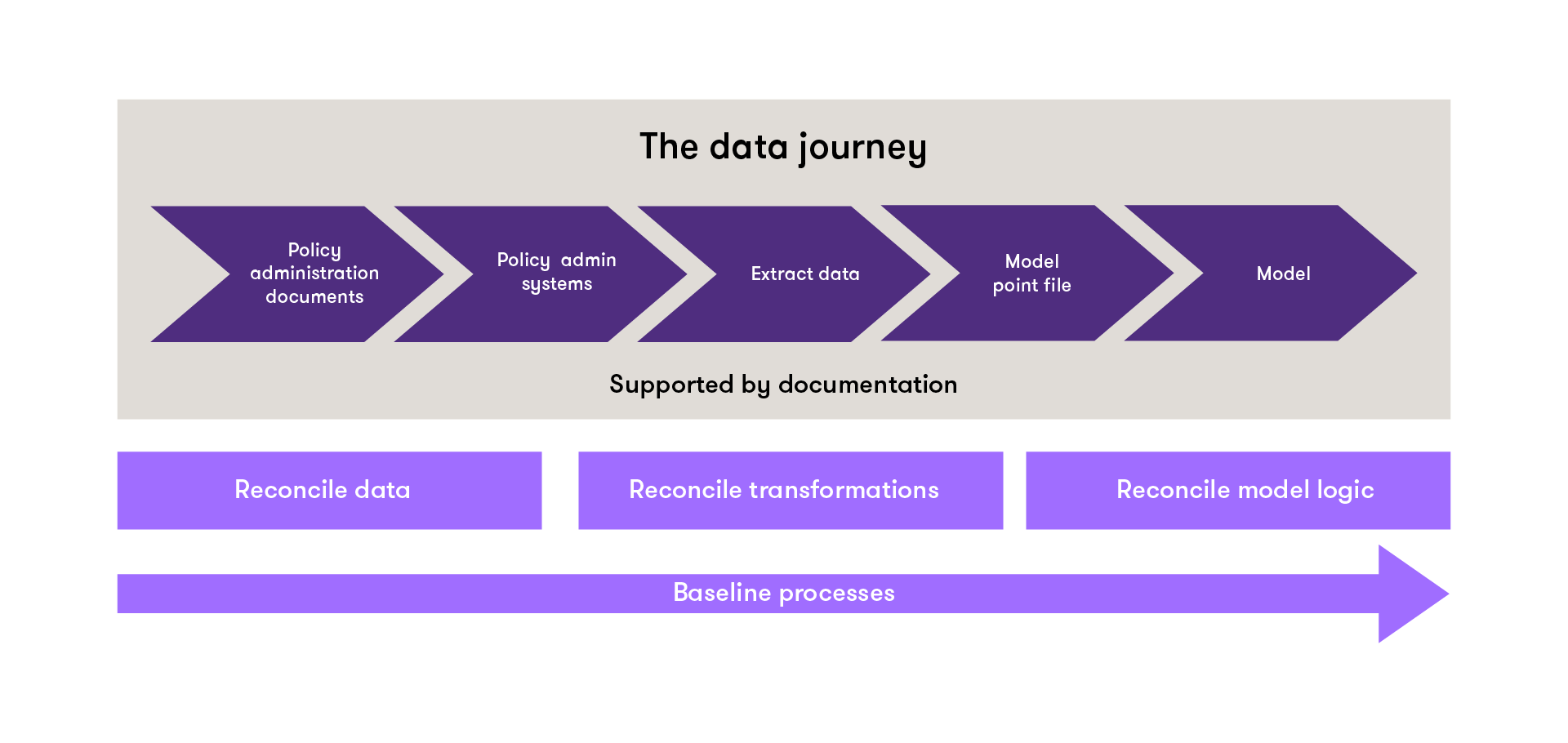
When documenting results from the baseline exercise, you should ensure that expert judgements and conclusions are well documented. Any issues identified should assessed for materiality and an action plan put in place to address them.
Actuarial models rarely use raw data. They rely on transformed data in the form of model point files. Transformations range from simple mappings of gender to a 1 or 0, to complex logic that influence how a policy is modelled. It’s important that model-point transformations are reviewed to make sure they behave as expected. In particular the transformations need to be consistent with how the valuation engine expects the inputs to look. The valuation engine itself ideally shouldn’t contain any data transformations, but sometimes it can happen, particularly in in-house models.
Many insurers may have old product lines, which tend to have poor-quality data and documentation, with multiple inaccuracies and gaps. Portfolio transfers or M&A can be particularly complex if you haven’t simplified it or aligned it with your own data structures. Problems tend to be greater if old product lines are still stored on legacy systems.
Baselining examines end-to-end processes, so it’s essential to understand the full environment the model operates in. This covers the whole valuation process and associated controls, including the source policy data as a key input, through to output from the valuation engine. Understanding the entire process also helps to reduce the risk at handover points, where data moves from one system or process to another.
You probably won’t be able to baseline every policy in your book, so you’ll need to take a sample that reflects the range of products and features your policies collectively offer. Choosing the policies for inclusion is tricky. While you can use a risk-based approach, it’s important to make sure you don’t introduce any bias – for example, you may overlook policies with a low reserve and data issues in favour of high reserve policies. Ideally, you want a sample that demonstrates treatment of all product features over time, initially focusing on the more complex characteristics.
As with the sampling size, you won’t be able validate all fields for model inputs. Once again, a risk-based approach will help you identify the critical data fields with the most material impact on the results. This may require expert judgement or quantitative methods, such as sensitivity analysis. Both approaches have their pros and cons. A risk-based approach is quicker, but expert judgement is subjective. On the other hand, quantitative methods offer greater objectivity but can be a lot of work. Ultimately, you may need a blended approach to maximise the benefits from each. Whichever approach you take, you need to document it appropriately, including any assumptions behind the expert judgement.
Firms generally don’t spend long on their model documentation, so it tends to be of limited value for model baselining. This is compounded by the complexity of insurance models, so it’s essential to use simple language when documenting model processes. You could consider replica spreadsheets to record code, or other innovative approaches to make model documents easier to read and understand. While it may take longer to effectively document your model processes, it's worth it. Poor documentation can increase the risk of errors and also pose a problem in terms of succession planning. If the original model builder departs the company or team, poor documentation can leave you without anyone that really understands how the model works. Robust model documentation practices and policies will help you manage model risk and add value to your business.
Baselining is a big undertaking, so it needs sufficient budget and resources to be effective. The exercise will also undoubtedly flag some issues for remediation, which will need additional resources and investment to resolve, but that shouldn’t be a deterrent. Model risks that crystallise can have significant consequences that outweigh investment in model-risk controls and assurance processes. You also need to consider how you’ll balance baselining in the first line, with model risk assurance in the second. As insurance firms continue to build their data science capabilities, data, and model issues could become quicker to spot. Over time, this could reduce the cost of baselining and give your team greater assurance over model risk.
Firms need to decide how often to perform model baselining. While resourcing will be one factor, it could also impact your audits and reduce the cost. Auditors often ask for results of baselining activity, so a recent baseline can be helpful – especially as most firms change auditors every few years. Frequency really depends on your model-risk appetite and your unique risk profile. You may also want to undertake ad-hoc baselining in response to major model changes, system migrations, or product launches.
Good governance is essential to manage both model risk and the business processes that surround it. As such, it’s important to regularly review your model-related business processes to make sure they remain up to date and fit for purpose. Strengthening these governance and oversight processes, will keep insurers in step with banks – and ready for when regulatory scrutiny inevitable turns to the insurance sector.
Model baselining is nothing new and has been a mainstay of risk management to make sure models are appropriate and fit-for-purpose. Investing time and resources to baselining your models will offer your stakeholders greater assurance over their use.
There are a number of other activities related to baselining that you may need to consider, including:
Over time it’s also important to review your baselining processes to ensure they're appropriate for current business needs. This is particularly important for legacy products, which can get left behind due to poor data and legacy systems. You should also consider your broader model inventory, using it to identify other types of models to baseline – here we’ve been looking at the best liability model, but manuals and capital models should be considered too.
For more insight and guidance, get in touch with Simon Perry, Ken Man, Klass DeVries, and Penny Street.
![]()





